



哈希表
「哈希表 hash table」,又称「散列表」,它通过建立键 key 与值 value 之间的映射,实现高效的元素查询。
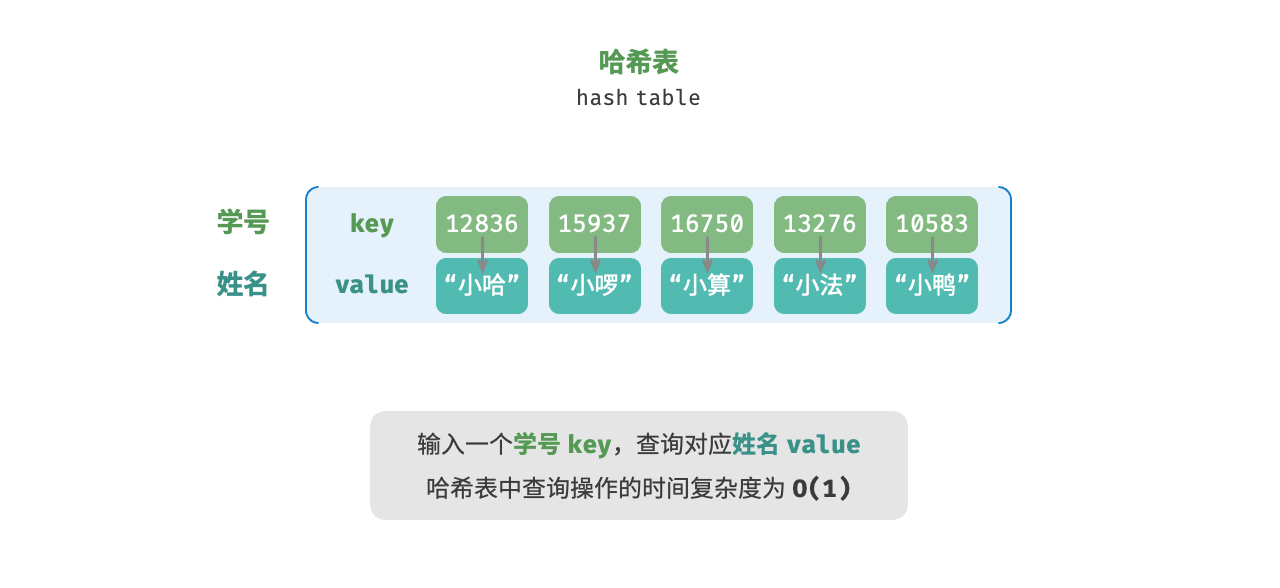
哈希表简单实现
通过哈希函数得到 key 对应的键值对在数组中的存储位置。
哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。
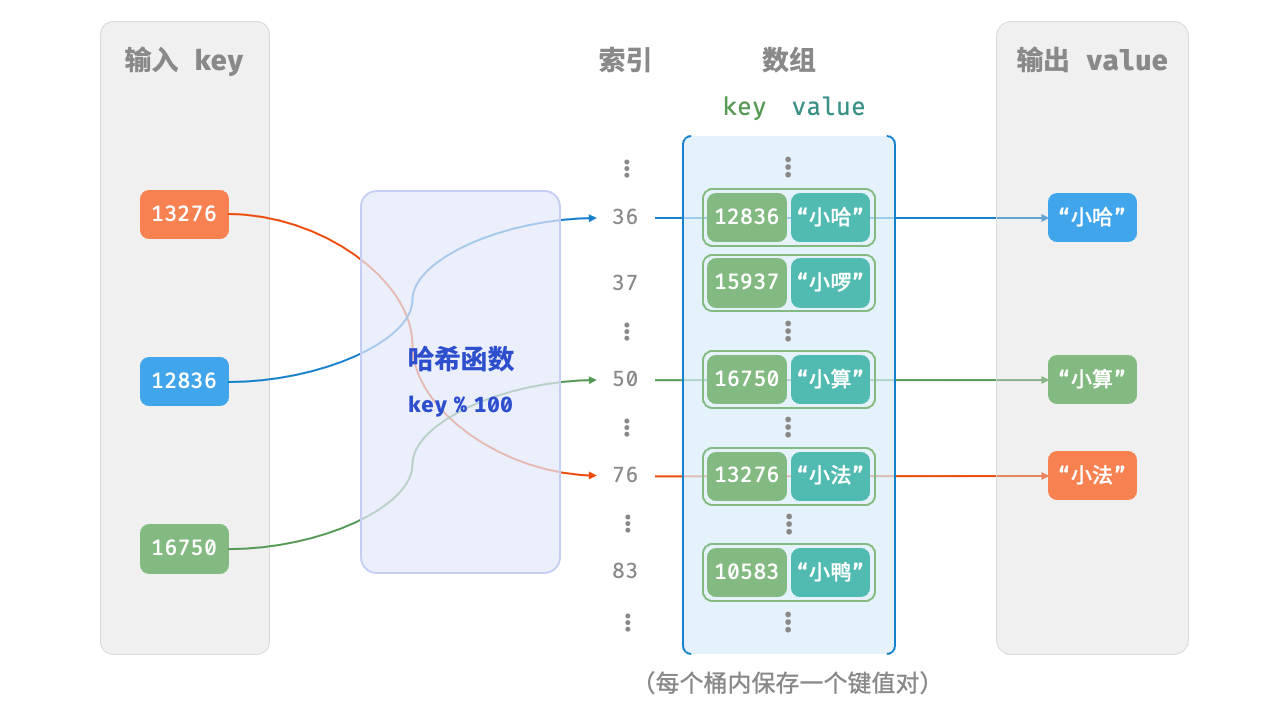
/* 键值对 int->string */
typedef struct {
int key;
char *val;
} Pair;
/* 基于数组实现的哈希表 */
typedef struct {
Pair *buckets[HASHTABLE_CAPACITY];
} ArrayHashMap;
/* 构造函数 */
ArrayHashMap *newArrayHashMap() {
ArrayHashMap *hmap = malloc(sizeof(ArrayHashMap));
return hmap;
}
/* 析构函数 */
void delArrayHashMap(ArrayHashMap *hmap) {
for (int i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
free(hmap->buckets[i]->val);
free(hmap->buckets[i]);
}
}
free(hmap);
}
/* 添加操作 */
void put(ArrayHashMap *hmap, const int key, const char *val) {
Pair *Pair = malloc(sizeof(Pair));
Pair->key = key;
Pair->val = malloc(strlen(val) + 1);
strcpy(Pair->val, val);
int index = hashFunc(key);
hmap->buckets[index] = Pair;
}
/* 删除操作 */
void removeItem(ArrayHashMap *hmap, const int key) {
int index = hashFunc(key);
free(hmap->buckets[index]->val);
free(hmap->buckets[index]);
hmap->buckets[index] = NULL;
}
/* 获取所有键值对 */
void pairSet(ArrayHashMap *hmap, MapSet *set) {
Pair *entries;
int i = 0, index = 0;
int total = 0;
/* 统计有效键值对数量 */
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
entries = malloc(sizeof(Pair) * total);
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
entries[index].key = hmap->buckets[i]->key;
entries[index].val = malloc(strlen(hmap->buckets[i]->val) + 1);
strcpy(entries[index].val, hmap->buckets[i]->val);
index++;
}
}
set->set = entries;
set->len = total;
}
/* 获取所有键 */
void keySet(ArrayHashMap *hmap, MapSet *set) {
int *keys;
int i = 0, index = 0;
int total = 0;
/* 统计有效键值对数量 */
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
keys = malloc(total * sizeof(int));
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
keys[index] = hmap->buckets[i]->key;
index++;
}
}
set->set = keys;
set->len = total;
}
/* 获取所有值 */
void valueSet(ArrayHashMap *hmap, MapSet *set) {
char **vals;
int i = 0, index = 0;
int total = 0;
/* 统计有效键值对数量 */
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
vals = malloc(total * sizeof(char *));
for (i = 0; i < HASHTABLE_CAPACITY; i++) {
if (hmap->buckets[i] != NULL) {
vals[index] = hmap->buckets[i]->val;
index++;
}
}
set->set = vals;
set->len = total;
}
/* 打印哈希表 */
void print(ArrayHashMap *hmap) {
int i;
MapSet set;
pairSet(hmap, &set);
Pair *entries = (Pair *)set.set;
for (i = 0; i < set.len; i++) {
printf("%d -> %s\n", entries[i].key, entries[i].val);
}
free(set.set);
}哈希冲突与扩容
哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
将这种多个输入对应同一输出的情况称为「哈希冲突 hash collision」。
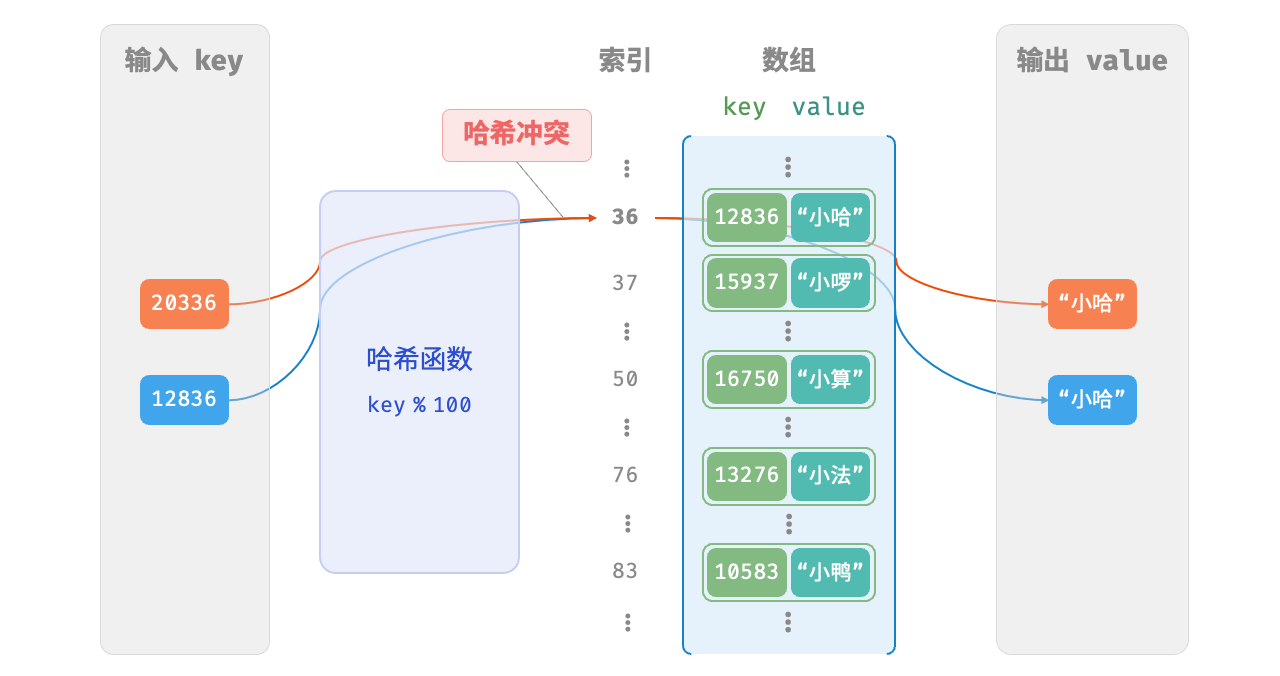
哈希表容量n越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,可以通过扩容哈希表来减少哈希冲突。
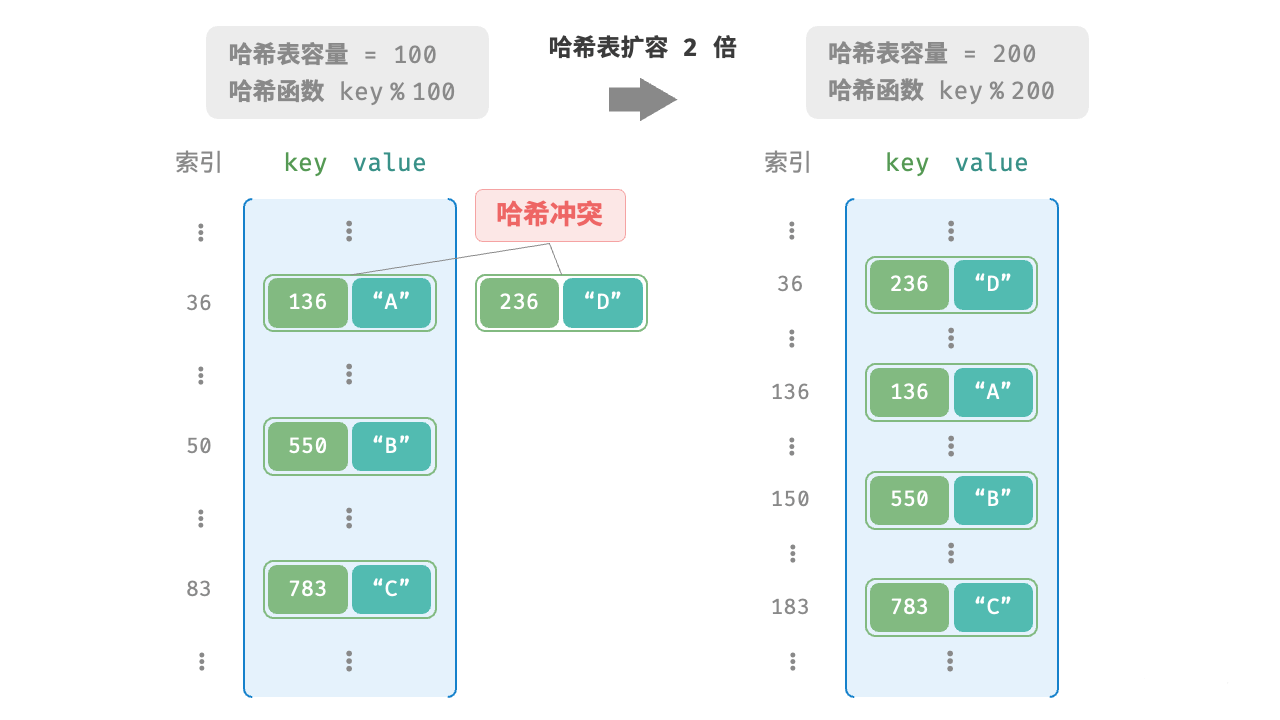
哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
「负载因子 load factor」是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表扩容至原先的 2 倍。
哈希冲突
通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。哈希冲突会导致查询结果错误,严重影响哈希表的可用性,因而改进策略
改良哈希表数据结构,使得哈希表可以在出现哈希冲突时正常工作。
仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良
链式地址
开放寻址
链式地址
/* 链表节点 */
typedef struct Node {
Pair *pair;
struct Node *next;
} Node;
/* 链式地址哈希表 */
typedef struct {
int size; // 键值对数量
int capacity; // 哈希表容量
double loadThres; // 触发扩容的负载因子阈值
int extendRatio; // 扩容倍数
Node **buckets; // 桶数组
} HashMapChaining;
/* 构造函数 */
HashMapChaining *newHashMapChaining() {
HashMapChaining *hashMap = (HashMapChaining *)malloc(sizeof(HashMapChaining));
hashMap->size = 0;
hashMap->capacity = 4;
hashMap->loadThres = 2.0 / 3.0;
hashMap->extendRatio = 2;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
return hashMap;
}
/* 析构函数 */
void delHashMapChaining(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
while (cur) {
Node *tmp = cur;
cur = cur->next;
free(tmp->pair);
free(tmp);
}
}
free(hashMap->buckets);
free(hashMap);
}
/* 哈希函数 */
int hashFunc(HashMapChaining *hashMap, int key) {
return key % hashMap->capacity;
}
/* 负载因子 */
double loadFactor(HashMapChaining *hashMap) {
return (double)hashMap->size / (double)hashMap->capacity;
}
/* 查询操作 */
char *get(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
// 遍历桶,若找到 key ,则返回对应 val
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
return cur->pair->val;
}
cur = cur->next;
}
return ""; // 若未找到 key ,则返回空字符串
}
/* 添加操作 */
void put(HashMapChaining *hashMap, int key, const char *val) {
// 当负载因子超过阈值时,执行扩容
if (loadFactor(hashMap) > hashMap->loadThres) {
extend(hashMap);
}
int index = hashFunc(hashMap, key);
// 遍历桶,若遇到指定 key ,则更新对应 val 并返回
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
strcpy(cur->pair->val, val); // 若遇到指定 key ,则更新对应 val 并返回
return;
}
cur = cur->next;
}
// 若无该 key ,则将键值对添加至链表头部
Pair *newPair = (Pair *)malloc(sizeof(Pair));
newPair->key = key;
strcpy(newPair->val, val);
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->pair = newPair;
newNode->next = hashMap->buckets[index];
hashMap->buckets[index] = newNode;
hashMap->size++;
}
/* 扩容哈希表 */
void extend(HashMapChaining *hashMap) {
// 暂存原哈希表
int oldCapacity = hashMap->capacity;
Node **oldBuckets = hashMap->buckets;
// 初始化扩容后的新哈希表
hashMap->capacity *= hashMap->extendRatio;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
hashMap->size = 0;
// 将键值对从原哈希表搬运至新哈希表
for (int i = 0; i < oldCapacity; i++) {
Node *cur = oldBuckets[i];
while (cur) {
put(hashMap, cur->pair->key, cur->pair->val);
Node *temp = cur;
cur = cur->next;
// 释放内存
free(temp->pair);
free(temp);
}
}
free(oldBuckets);
}
/* 删除操作 */
void removeItem(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
Node *cur = hashMap->buckets[index];
Node *pre = NULL;
while (cur) {
if (cur->pair->key == key) {
// 从中删除键值对
if (pre) {
pre->next = cur->next;
} else {
hashMap->buckets[index] = cur->next;
}
// 释放内存
free(cur->pair);
free(cur);
hashMap->size--;
return;
}
pre = cur;
cur = cur->next;
}
}
/* 打印哈希表 */
void print(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
printf("[");
while (cur) {
printf("%d -> %s, ", cur->pair->key, cur->pair->val);
cur = cur->next;
}
printf("]\n");
}
}
评论区